Zhipu AI Releases 'Glyph': An AI Framework for Scaling the Context…
Zhipu AI Releases ‘Glyph’: An AI Framework for Scaling the Context Length Through Visual-Text Compression
SEO Title:
Glyph by Zhipu AI: Scaling AI Context Length with Visual-Text Compression
Meta Description:
Discover how Zhipu AI’s Glyph framework revolutionizes AI context scaling by converting text into images, enabling 3-4x token compression while preserving accuracy.
Introduction
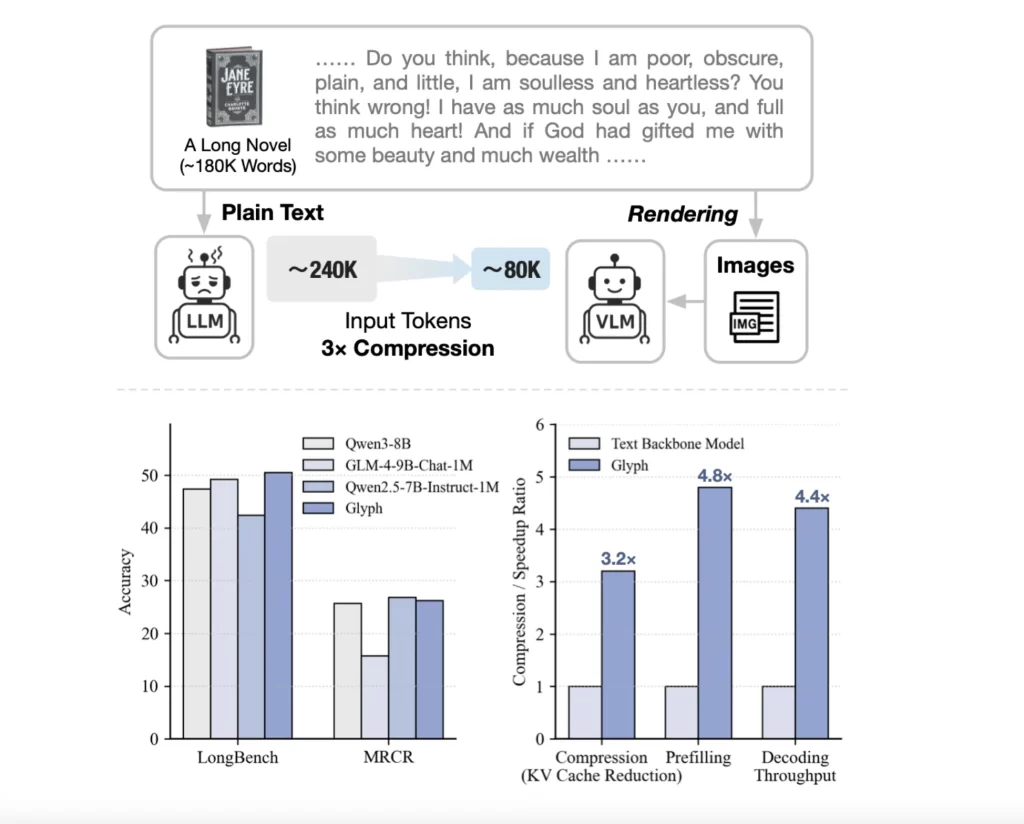
In the rapidly evolving world of artificial intelligence, handling long-context data efficiently is a major challenge. Traditional methods struggle with memory and computational constraints as token counts grow. Zhipu AI’s latest innovation, Glyph, addresses this issue by leveraging visual-text compression, allowing AI models to process vast amounts of text by converting it into images. This breakthrough enables 3-4x token compression without sacrificing accuracy, making it a game-changer for businesses and researchers dealing with large-scale data.
What is Glyph?
Glyph is an AI framework designed to scale context length by converting long textual sequences into images, which are then processed by a Vision-Language Model (VLM). By encoding text visually, Glyph reduces the number of tokens an AI model needs to process, significantly improving efficiency.
Key Features & Benefits
- Token Compression (3-4x Reduction) – Each visual token encodes multiple characters, allowing AI models to handle longer sequences efficiently.
- Preserved Semantics – Despite compression, the model retains the original meaning of the text.
- Improved Performance – Faster preprocessing, decoding, and fine-tuning compared to traditional text-based models.
- Scalability – Enables AI models with 128K context windows to process tasks requiring 1M tokens.
- Multimodal Learning – Enhances document understanding by integrating visual and textual data.
How Glyph Works
Glyph operates in three key stages:
1. Continual Pre-Training
- The VLM is trained on a large corpus of rendered text with diverse typography.
- Aligns visual and textual representations to ensure accuracy.
2. LLM-Driven Rendering Search
- Uses a genetic algorithm to optimize rendering parameters (font size, spacing, alignment, etc.).
- Evaluates different configurations to balance compression and accuracy.
3. Post-Training Fine-Tuning
- Refines the model using supervised fine-tuning and reinforcement learning.
- Includes an OCR alignment task to improve character recognition.
Use Cases in Business & Finance
Glyph’s ability to handle long-context data makes it valuable in several industries:
1. Financial Analysis & Reporting
- Automated Document Processing – Banks and financial institutions can analyze lengthy financial reports, contracts, and compliance documents efficiently.
- Risk Assessment – AI models can evaluate long historical data for fraud detection and risk modeling.
2. Legal & Compliance
- Contract Analysis – Law firms can process extensive legal documents with improved accuracy.
- Regulatory Compliance – Automatically extract and analyze regulatory texts for compliance checks.
3. Customer Support & Chatbots
- Long-Context Conversations – AI chatbots can maintain context over extended interactions without performance degradation.
- Knowledge Base Integration – Process large knowledge bases without token limitations.
4. Research & Academia
- Literature Review Automation – Researchers can analyze vast amounts of academic papers efficiently.
- Data-Driven Decision Making – Businesses can process large datasets for market trends and insights.
Setup & Cost
Glyph is open-source and available on GitHub and Hugging Face, making it accessible for developers and researchers. While the framework itself is free, users may need computational resources for training and deployment, depending on their use case.
Requirements:
- A Vision-Language Model (VLM) with strong OCR capabilities.
- GPU/TPU acceleration for efficient processing.
- Python environment with necessary libraries (PyTorch, Transformers, etc.).
Comparison with Alternatives
| Feature | Glyph | Traditional Text Models | Retrieval-Augmented Models |
|---|---|---|---|
| Token Compression | 3-4x | 1x | 1x (with retrieval latency) |
| Speed (Prefill/Decode) | 4.8x / 4.4x faster | Baseline | Slower due to retrieval |
| Memory Efficiency | High | Low (scales with tokens) | Moderate |
| Context Length Scaling | 1M+ tokens | Limited by token count | Limited by retrieval efficiency |
| Multimodal Support | Yes (text + images) | No | No |
Glyph outperforms traditional models in speed, memory efficiency, and scalability, while retrieval-augmented models suffer from latency and potential information loss.
Conclusion
Zhipu AI’s Glyph represents a major leap in AI’s ability to handle long-context data. By converting text into images and leveraging VLMs, it achieves unprecedented token compression without sacrificing accuracy. Businesses, researchers, and developers can now process million-token workloads efficiently, unlocking new possibilities in automation, analytics, and decision-making.
For those interested in implementing Glyph, the code, weights, and documentation are available on GitHub and Hugging Face.
Final Thoughts
Glyph’s innovative approach to visual-text compression sets a new standard for AI scalability. As businesses increasingly rely on AI for data-heavy tasks, tools like Glyph will be instrumental in driving efficiency and accuracy in automation and analysis.
Would you like to explore how Glyph can be integrated into your workflow? Let us know in the comments!