Sigmoidal Scaling Curves Make Reinforcement Learning RL…
Sigmoidal Scaling Curves Make Reinforcement Learning (RL) Post-Training Predictable for LLMs
SEO Title:
How Sigmoidal Scaling Curves Revolutionize Reinforcement Learning for AI Models
Meta Description:
Discover how sigmoidal scaling curves and ScaleRL make reinforcement learning (RL) post-training predictable, improving AI model performance with data-driven insights.
Introduction
Reinforcement Learning (RL) has become a cornerstone of AI development, particularly in fine-tuning large language models (LLMs). However, unlike pre-training, RL post-training has lacked predictable scaling rules, leading to costly trial-and-error experiments. A groundbreaking study by Meta, UT Austin, UCL, Berkeley, Harvard, and Periodic Labs introduces a sigmoidal scaling framework that models RL progress more accurately than traditional power-law fits. This innovation, combined with a tested recipe called ScaleRL, enables AI teams to forecast performance improvements before investing massive computational resources.
Key Features & Benefits of Sigmoidal Scaling in RL
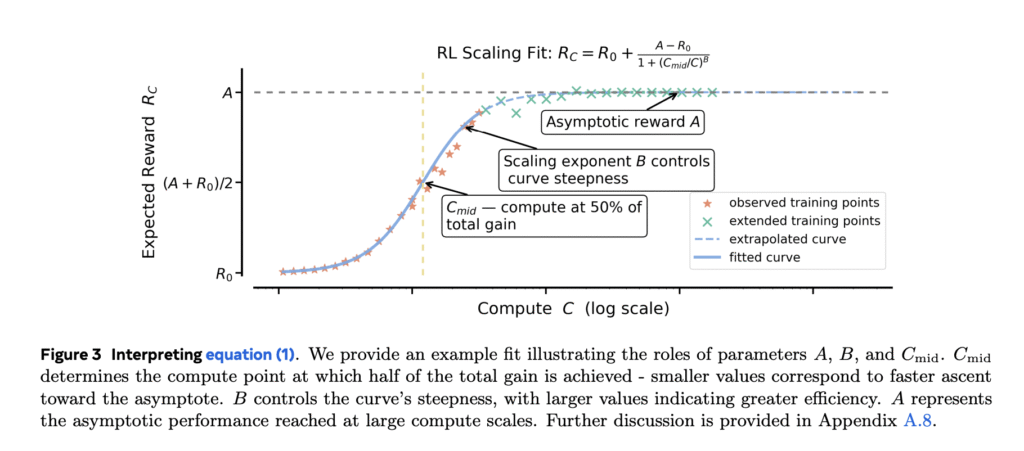
1. Sigmoidal vs. Power-Law Fits
- Sigmoidal curves better model bounded metrics (e.g., pass rates, mean rewards) compared to power-law fits.
- They provide stable extrapolations from smaller runs to larger budgets, reducing uncertainty in long-term training decisions.
- Unlike power-law models, sigmoidal fits exclude noisy early-stage data (~1.5k GPU-hours) for more reliable predictions.
2. ScaleRL: A Predictable RL Recipe
ScaleRL is not just an algorithm but a combination of optimized techniques that ensure consistent scaling:
- Asynchronous Pipeline RL (generator-trainer split) for efficient off-policy learning.
- CISPO (truncated importance-sampling REINFORCE) as the RL loss function.
- FP32 precision at logits to prevent numerical mismatches.
- Prompt-level loss averaging and batch-level advantage normalization for stability.
- Forced length interruptions to prevent runaway token generation.
- Zero-variance filtering to discard uninformative prompts.
- No-Positive-Resampling to exclude high-pass-rate prompts (≥0.9) in later epochs.
3. Early Forecasting & Cost Efficiency
- After just 1–2k GPU-hours, teams can fit a sigmoidal curve to predict whether scaling to 10k–100k GPU-hours is worthwhile.
- This eliminates wasteful spending on underperforming models.
Use Cases in Business & Finance
1. AI-Driven Financial Forecasting
- RL fine-tuning can optimize trading algorithms by predicting market movements.
- Sigmoidal scaling ensures that computational investments align with expected performance gains.
2. Automated Customer Support Chatbots
- Businesses can fine-tune LLMs to improve response accuracy and efficiency.
- Predictable scaling helps allocate resources effectively.
3. Fraud Detection Systems
- RL models can be fine-tuned to detect anomalies in real-time transactions.
- Sigmoidal curves help determine the optimal training budget for maximum accuracy.
Setup & Cost
Implementation Steps
- Data Preparation: Collect high-quality RL training data.
- Model Selection: Choose an LLM architecture (e.g., 8B dense or Llama-4 17B×16 MoE).
- ScaleRL Integration: Apply the ScaleRL recipe (asynchronous pipeline, CISPO loss, FP32 logits, etc.).
- Curve Fitting: Monitor training progress and fit sigmoidal curves after ~1.5k GPU-hours.
- Extrapolation & Decision-Making: Use the fitted curve to predict performance at higher compute budgets.
Cost Considerations
- GPU-Hours: The study validated results using >400,000 GPU-hours, with single runs extending to 100k GPU-hours.
- Cloud vs. On-Premise: Costs vary based on infrastructure (AWS, Google Cloud, or private clusters).
Comparison with Alternatives
| Feature | ScaleRL (Sigmoidal Scaling) | Traditional Power-Law Fits | Other RL Recipes (e.g., DeepSeek, Qwen-2.5) |
|---|---|---|---|
| Predictability | High (stable extrapolations) | Low (unreliable for bounded metrics) | Moderate (depends on model) |
| Compute Efficiency | Optimized (asynchronous pipeline, CISPO loss) | Less efficient (no structured scaling) | Varies (some lack systematic optimization) |
| Asymptotic Performance | Higher (better ceiling) | Unpredictable | Lower (compared to ScaleRL) |
| Early Forecasting | Yes (after ~1.5k GPU-hours) | No (requires high compute) | Limited |
Conclusion
The introduction of sigmoidal scaling curves and ScaleRL marks a significant leap in making RL post-training predictable. By fitting sigmoidal models early, AI teams can make data-driven decisions on scaling, reducing wasted computational resources. Businesses in finance, customer support, and fraud detection can leverage this framework to optimize AI performance efficiently.
For further details, check out the research paper and explore related tutorials on GitHub.
Final Thoughts
Sigmoidal scaling transforms RL from a costly guessing game into a forecastable engineering process. By separating ceiling-moving (model size, generation length) and efficiency-shaping (loss aggregation, normalization) factors, teams can prioritize high-impact changes first. This innovation is set to redefine how AI models are fine-tuned in the future.
Would you like to explore specific implementations or case studies in more detail?