Baidu’s PaddlePaddle Team Releases PaddleOCR-VL (0.9B): a…
Baidu’s PaddlePaddle Team Releases PaddleOCR-VL (0.9B): A Game-Changer for Document Processing
SEO Meta Description
Discover how Baidu’s PaddleOCR-VL (0.9B) revolutionizes document parsing with multilingual support, structured outputs, and real-time processing. Learn its key features, use cases, and how it compares to alternatives.
Introduction
In today’s data-driven world, businesses and individuals rely on AI-powered tools to automate workflows, analyze complex documents, and extract valuable insights. Baidu’s PaddlePaddle team has introduced PaddleOCR-VL (0.9B), a cutting-edge vision-language model designed for end-to-end document parsing. This tool excels in converting complex, multilingual documents—including text, tables, formulas, charts, and handwriting—into structured Markdown and JSON formats with state-of-the-art accuracy.
Whether you’re in finance, legal, or research, PaddleOCR-VL offers a powerful solution for document intelligence. Let’s explore its features, benefits, and real-world applications.
Key Features of PaddleOCR-VL (0.9B)
1. Multilingual & Multimodal Support
PaddleOCR-VL supports 109 languages, making it ideal for global businesses dealing with diverse document formats. It processes:
- Text (including small scripts)
- Tables
- Mathematical formulas
- Charts and graphs
- Handwritten notes
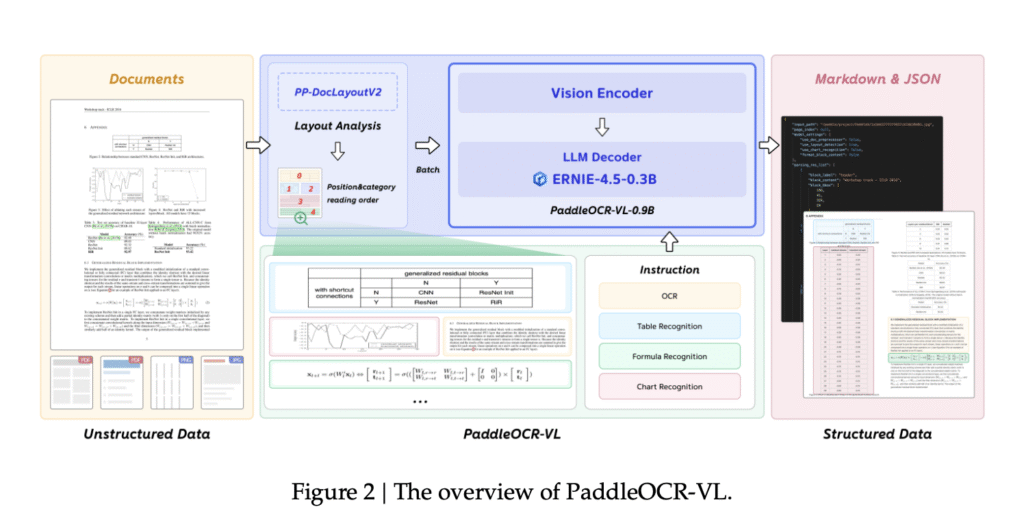
2. Two-Stage Processing Pipeline
The model operates in two stages:
- Stage 1 (PP-DocLayoutV2): Detects and classifies document regions using RT-DETR and predicts reading order via a pointer network.
- Stage 2 (PaddleOCR-VL-0.9B): Recognizes elements based on the detected layout, ensuring high accuracy.
This decoupled approach reduces latency and improves stability, especially for dense, multi-column documents.
3. Native-Resolution Processing with NaViT-Style Encoder
Unlike traditional models that resize or tile images, PaddleOCR-VL uses a NaViT-style dynamic-resolution encoder, preserving fine details in small scripts, formulas, and handwriting. This leads to:
- Lower hallucination rates
- Better text-dense performance
- Faster inference speeds
4. Structured Outputs (Markdown & JSON)
The model generates structured outputs, making it easy to integrate with downstream applications such as:
- Data analytics platforms
- Document management systems
- AI-driven automation tools
5. Optimized for Real-World Deployment
PaddleOCR-VL is designed for low-latency inference, making it suitable for production environments where speed and accuracy are critical.
Business & Financial Use Cases
1. Automated Document Processing in Finance
Banks and financial institutions handle vast amounts of paperwork, including contracts, invoices, and reports. PaddleOCR-VL can:
- Extract key financial data from PDFs and scanned documents
- Automate invoice processing and expense reporting
- Improve compliance by accurately parsing regulatory documents
2. Legal & Contract Analysis
Law firms and legal departments can use PaddleOCR-VL to:
- Parse complex legal documents with tables and formulas
- Extract clauses and metadata for contract analysis
- Reduce manual review time with AI-assisted document summarization
3. Research & Academic Publishing
Researchers and publishers can automate:
- Extraction of tables and figures from research papers
- Conversion of handwritten notes into digital formats
- Structured data extraction for metadata tagging
4. Healthcare & Medical Records
Hospitals and healthcare providers can streamline:
- Patient record digitization
- Extraction of lab results and prescription details
- Compliance with HIPAA and other regulatory standards
Setup & Cost
Installation & Deployment
PaddleOCR-VL is available via Hugging Face and can be integrated into existing workflows with minimal setup. Key steps include:
- Download the model from the official repository.
- Install dependencies (Python, PaddlePaddle, etc.).
- Integrate with your application using provided APIs.
Pricing & Licensing
As an open-source tool, PaddleOCR-VL is free to use, making it accessible for startups and enterprises alike. However, cloud-based deployment may incur costs depending on the infrastructure used.
Comparison with Alternatives
| Feature | PaddleOCR-VL (0.9B) | Tesseract OCR | Amazon Textract | Google Document AI |
|---|---|---|---|---|
| Multilingual Support | 109 languages | Limited | Yes | Yes |
| Handwriting Recognition | Yes | Limited | No | Yes |
| Table & Formula Parsing | Yes | No | Yes | Yes |
| Structured Output (JSON/Markdown) | Yes | No | Yes | Yes |
| Latency & Efficiency | Optimized for real-time | Slower | Moderate | Moderate |
| Cost | Free (open-source) | Free | Paid | Paid |
PaddleOCR-VL stands out due to its open-source nature, multilingual capabilities, and structured outputs, making it a cost-effective alternative to cloud-based solutions.
Conclusion
Baidu’s PaddleOCR-VL (0.9B) is a powerful AI tool that automates document processing with unparalleled accuracy and efficiency. Its ability to handle multilingual, multimodal documents while maintaining low-latency performance makes it a top choice for businesses in finance, legal, healthcare, and research.
By leveraging NaViT-style encoding and structured outputs, PaddleOCR-VL simplifies document intelligence, reducing manual work and improving decision-making. Whether you’re a developer, business owner, or researcher, this tool can streamline your workflows and unlock new efficiencies.
Ready to try PaddleOCR-VL?
Stay updated with the latest in AI and machine learning by following Marktechpost on Twitter and joining their SubReddit.